
Business and backup strategy
Backup and restore procedures depend heavily on the amount of data, system availability and export period. Business strategy should define a disaster recovery plan within a business continuity plan.
In an ideal
Recovery Point Objective (RPO): the maximum acceptable time interval between the last valid back-up and the time when the error occurred.
Recovery Time Objective (RTO): the time needed to restore the database and return it to an operational state.
Three basic backup methods in PostgreSQL
- SQL dump – this dump method generates a text file with SQL commands
that that can be used to recreate the Postgres cluster, one database or a specific table. Commands pg_dump and pg_dumpall can be used only for logical exports and are not suitable for large databases. The export and import of large databases usuallytakes too long. - File system level backup – is not suitable for 24/7 production databases because the server must be shut down during backup. With file system backup it is impossible to restore only one table.
- Continuous Archiving and Point-In-Time-Recovery (PITR) – this is a combination of file-system-level backup with a backup of the WAL files (Write Ahead Log). CA and PITR
is more complex to administer than the other two methods but it has some significant benefits and is a preferred backup method. WAL files are continuously archived in a secure location and can be used for PITR. WAL files provide durable database transactions and protect a database from losing data.
PostgreSQL comes with tools that are sufficient to perform backup, incremental/continuous backup and point-in-time-recovery from backup (pg_basebackup, archive_command, restore_command, pg_archivecleanup …).
Before using any additional tools that can help you, it is important to be familiar with backup and restore procedures using these basic tools.
Database configuration
In order to meet business requirements, it is necessary to properly configure database configuration parameters. PostgreSQL official documentation explains in detail all the parameters, and a useful online configuration tool is
# Replication
wal_level = replica
max_wal_senders = 10
synchronous_commit = on
wal_keep_segments = 1290 # Checkpointing:
checkpoint_timeout = '15 min'
checkpoint_completion_target = 0.9
max_wal_size = '10240 MB'
min_wal_size = '5120 MB'# WAL archiving
archive_mode = on # having it on enables activating P.I.T.R. at a later time without restart# pgBackRest
archive_command = 'pgbackrest --stanza=hivetest02 archive-push %p'# WAL writing
wal_compression = on
wal_buffers = -1 # auto-tuned by Postgres till maximum of segment size (16MB by default)
wal_writer_delay = 200ms
wal_writer_flush_after = 1MBThe above parameters are related to WAL and backup in the
It is very important that the PostgreSQL database and backup process is under a constant monitoring process! A database without control can become inaccessible very quickly. Some nice tools for monitoring PostgreSQL (pgwatch2 and pgBadger) are going to be described in the next blog.
If the file system containing WAL files fills up, PostgreSQL will do a PANIC shutdown.
Choose the right backup tools
As mentioned above, Continuous Archiving and Point-In-Time-Recovery (PITR) is not a trivial method. There are various tools/disaster recovery solutions for PostgreSQL that can help. Some of them
pg_rman is a fast, simple configuration backup and restore tool developed by NIPPON TELEGRAPH AND TELEPHONE CORPORATION but with some limitations. One of them is that pg_rman requires
Barman – Backup and Recovery Manager is an Open Source administration tool for disaster recovery of PostgreSQL servers. It allows centralized and remote backups of multiple servers and has a lot of features. Comparing Barman and pgBackRest we have concluded that pgBackRest has an advantage in parallel processing.
pgBackRest is a backup and restore solution that can be used for the largest databases. Parallel processing and compression reduces recovery time. One central backup location can be used for all PostgreSQL databases. The user guide, command references and configuration references are described in detail.
pgBackRest has a lot of options, it’s not very easy to configure as is the case with pg_rman but it offers a lot more features that can be crucial in the production environment of mass volume databases.
- Parallel Backup & Restore –
solves the compression bottleneck with parallel processing - Local or Remote Operation – restore and archive locally or remotely via SSH
- Full, Incremental, & Differential Backups
- Backup Rotation & Archive Expiration
- Backup Integrity
- Page Checksums
- Backup Resume
- Streaming Compression & Checksums
- Delta Restore
- Parallel, Asynchronous WAL Push & Get
- Tablespace & Link Support
- Amazon S3 Support
- Encryption
- Compatibility with PostgreSQL >= 8.3
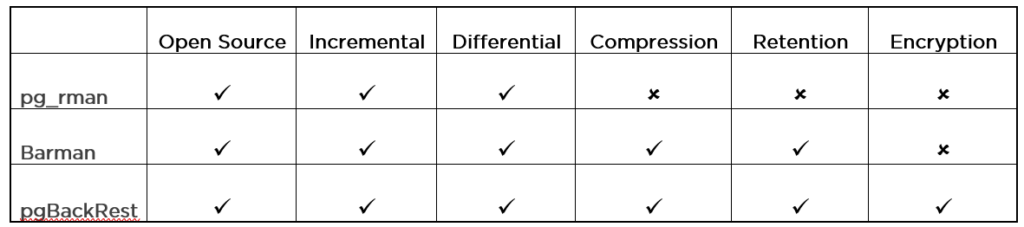
pgBackRest – a backup tool suitable for the largest databases
For basic pgBackRest setup we need:
- one host with a central repository where pgBackRest stores backups and archives WAL segments
- database cluster with PostgreSQL database
- installed
pgbackrest rpm package from postgresql.org, rpm must be installed on repo andpostgres host (yum installpgbackrest ) - passwordless ssh – agents communicate between the hosts via ssh
- configure stanza – stanza is the configuration for a database cluster
- configure retention – numbers of full, diff and
incr backups kept in the repository. Old backups will be automatically deleted - check the configuration
- perform a backup – just run pgBackRest with the backup command
pgbackrest --stanza=ipam --type=full backup- schedule a backup in cron
For restore pgBackRest have a few options: delta option, restore selected database option and restore Point-in-Time Recovery. Point-in-Time Recovery (PITR) allows the WAL to be played from the last backup to a specified time, transaction id, or recovery point.
Example of recovery command with target time option:
pgbackrest --stanza=ipam --delta \
--type=time "--target=2019-02-20 14:15:00.000000+01" restore pgBackRest is free and open source software under the MIT license and can be used for personal or commercial purposes without any limitations.
Trained DevOps team is essential
An ordinary working day can easily turn into a nightmare and the only way to successfully overcome an accident is careful planning, education
Finally, we need to emphasize once again that the backup does not mean anything if we are not sure that the backup is valid and that we can at any time restore the data!