
Silosna organizacija je loše rješenje za efikasno upravljanje uslugama u podatkovnim centrima
Brojni pružatelji usluga podatkovnog centra uslugu IaaS-a (engl. Infrastructure as a Service) temelje na VMware-ovoj tehnološkoj platformi koja se smješta na standardnu poslužiteljsku infrastrukturu i sustavima za pohranu podataka (SAN – engl. Storage Area Network). Usluga IaaS-a se često kombinira s poslovnim komunikacijskim uslugama koje se temelje na mrežnoj infrastrukturi samog pružatelja usluga. Nažalost, u takvim organizacijama najčešće postoje odvojeni tehnički timovi koji su odgovorni za nadzor i upravljanje VMware platformom, računalnom infrastrukturom, sustavima pohrane podatka i mrežom. Ovakav silosno organizirani pristup ni na koji način nije od koristi ni poslovanju pružatelja niti njegovim korisnicima.
Striktna podjela odgovornosti, koja se u prošlosti smatrala dobrim primjerom prakse u okolinama pružatelja usluga, redovito uzrokuje manjak razmjene informacije između različitih odjela što za posljedicu ima pojavu da se bilo kakva degradacija performansi usluga ili ispad dijela sustava u paraleli rješava u svim tehničkim odjelima. Naravno, dolazi do uobičajene neadekvatne komunikacije, okrivljavanja, guranja problema u drugi odjel, a sve za posljedicu ima bespotreban gubitak vremena kod otkrivanja uzroka i otklona problema.
Na dijagramu ispod opisan je jedan tipičan primjer ranije opisane situacije.
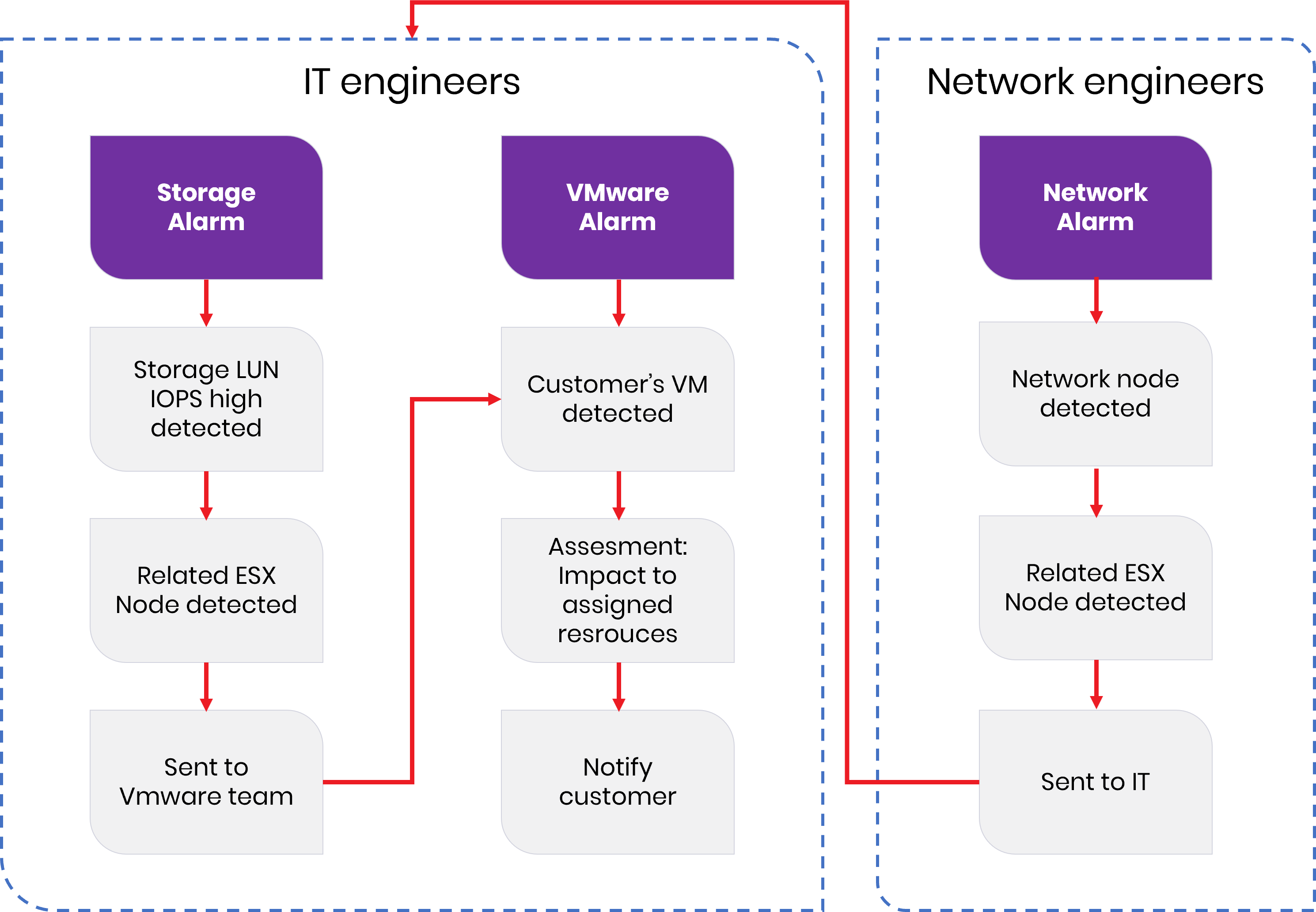
Zamislimo sada situaciju u kojoj korisnik pokrene nekakvu aktivnost (npr. pokrene procesiranje velike količine podataka) koja zahtijeva velike resurse mreže, sustava za pohranu podataka i virtualnih poslužitelja. Često se događa da korisnik nije zakupio dostatne resurse za takvu aktivnost, ali jednostavno toga nije svjestan. Korisnik je svojom aktivnošću uzrokovao preopterećenje dijela platforme i/ili mreže, a svaki od sustava koji služe pružanju usluge korisniku zasebno i često simultano generiraju alarme za svoju domenu.
Mrežni odjel je svjestan samo mrežnih alarma te prirodno reagira kao da se radi o isključivo mrežnom problemu. U isto vrijeme IT inženjeri dobivaju alarme virtualne platforme te započinju s otklonom problema neovisno o “mrežašima”. Tehnički timovi koji pripadaju različitim silosima jednostavno nisu svjesni da rješavaju isti problem.
Naravno, korisniku usluga podatkovnog centra sve izgleda jako loše. Korisnik je nezadovoljan te brzo okarakterizira pružatelja kao nesposobnog, nekompetentnog itd. Naravno, loš glas se brzo širi i ugrožen je ugled pružatelja usluga.
Postavlja se pitanje kako odgovoriti na ovaj izazov?
Krovni sustav nadzora VMware platforme i mreže kao odgovor na izazove silosne organizacije
Najlogičniji pristup rješavanju problema lokalizacije uzroka odvojenih i naočigled nepovezanih alarma koji dolaze iz različitih domena je njihova međusobna korelacija. Potrebno je uspostaviti objedinjeni pregled svih alarma na jednom mjestu. Drugim riječima, potreban je krovni (engl. umbrella) nadzorni sustav za sve domene mreže i platformi.
Konsolidacijom alarma na jednom mjestu u okviru krovnog sustava omogućena je korelacija alarma upotrebom korelacijskih algoritama. Detekcijom specifične korelacije različitih alarma generira se sintetički alarm kojeg vide svi tehnički odjeli. Nadalje, procesom obogaćivanja (engl. enrichment) krovni sustav dodaje podatke o afektiranom korisniku, njegovim uslugama, ponašanju korisnika te se dodaje informacija o afektiranom virtualnom poslužitelju, datastore-u i mrežnom uređaju.
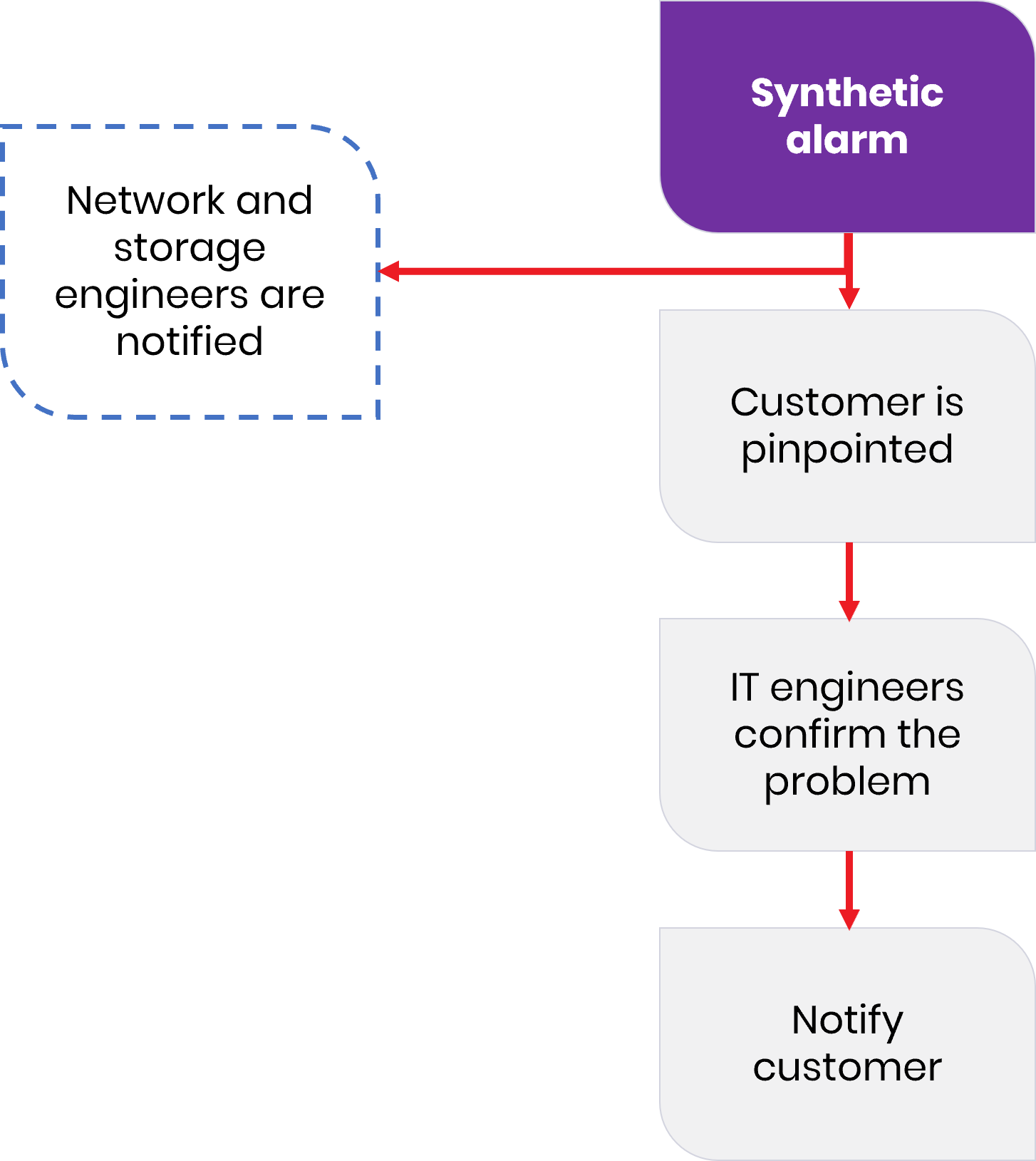
Vratimo se sada na ranije opisanu situaciju s korisnikom koji nema dostatne resurse. Kada postoji krovni sustav na nadzor i upravljanje, stvari izgledaju bitno drugačije. Tehnički tim koji je odgovoran za podršku korisnicima vidi u čemu je problem te može odmah kontaktirati korisnika, obavijestiti ga o situaciji i smanjiti mogućnost eskalacije. Prodajni predstavnik pružatelja podatkovnih usluga se automatski obavještava o nastaloj situaciji te mu se pruža mogućnost korisniku ponuditi nadogradnju kapaciteta usluga koje koristi. Korisnik dobiva pravovremenu informaciju, odgovarajuću ponudu, a zadovoljstvo reakcijom na nastalu situaciju nagrađuje vjernošću postojećem pružatelju. Upravo je ovo cilj uspostave izvrsnosti u pružanju usluge.
Ilustracija ispod također pokazuje bitno pojednostavljen tok događaja u tehnici.
Kako to radi UMBOSS?
UMBOSS prikuplja sve događaje i podatke o performansama VMware platforme (hypervisor-a, poslužitelja i sustava za pohranu podataka), mrežne infrastrukture, te ih konsolidira na jedno mjesto. Tako konsolidirani podaci se obogaćuju kontekstualnim podacima te se na njih primjenjuju različiti korelacijski algoritmi. Inženjeri podatkovnog centra vide sve alarme i podatke o performansama u UMBOSS Portalu koji omogućuje konsolidirani pogled od 360° na mrežu, uluge, korisnike – sve na jednom mjestu.
Koristeći Automatic Discovery and Reconciliation (ADM) Module, UMBOSS otkriva sve resurse virtualizacijske platforme, mreže i sustava za pohranu podataka. Svi otkriveni resursi se dodaju u nadzor koristeći UMBOSS Fault Management (FM) i UMBOSS Performance Management (PM).
Podaci iz VMware platforme, fizičkih i virtualnih poslužitelja, sustava za pohranu podataka i mreže se prikupljaju koristeći dedicirane kolektore podataka. Podaci koji su specifični za VMware platformu se prikupljaju koristeći standardni VMware REST API (npr. iz VMware vCenter-a) ili koristeći Kafkabus. Podaci iz sustava za pohranu podataka se prikupljaju kroz API sučelja kontrolera ili čak neposredno putem CLI sučelja. Mrežni podaci se prikupljaju putem SNMP-a ili npr. Kafka bus-a kada se radi o SDN kontroleru. Sve integracije implementiraju UMBOSS certificirani inženjeri.
Benefiti za pružatelje usluga podatkovnog centra i korisnike
Instalacijom UMBOSS krovnog sustava za nadzor mrežni i IT inženjeri postižu brojne prednosti:
- Koordinirana lokalizacija i otklon kvara suradnjom svih tehničkih odjela zahvaljujući objedinjenom pogledu na infrastrukturu i usluge;
- Brža detekcija i otklon problema;
- Pravodobna i precizna povratna informacija krajnjim korisnicima uz manje opterećenje za pozivni centar;
- Izvještaji o kvaliteti usluga se generiraju automatski i šalju korisnicima;
- Pružatelj usluga i korisnik razumiju kada je vrijeme za nadogradnju postojećeg servisa;
- Zadovoljniji korisnici koji su informirani i osjećaju se dijelom operacija pružatelja usluga.